老罗的 Android 之旅阅读笔记(Dalvik/ART 虚拟机篇)
Dalvik
Dalvik Heap
Dalvik 的堆空间分为 Zygote Heap 和 Active Heap
Android 系统的第一个 Dalvik 虚拟机是由 Zygote 进程创建的。应用程序进程是由 Zygote 进程 fork 出来的。也就是说应用程序进程使用了一种 写时拷贝技术(COW)来复制了 Zygote 进程的地址空间。这意味着一开始的时候,应用程序进程和 Zygote 进程共享了同一个用来分配对象的堆。然而,当 Zygote 进程或者应用程序进程对该堆进行写操作时,内核就会执行真正的拷贝操作,使得 Zygote 进程和应用程序进程分别拥有自己的一份拷贝。
拷贝是一件费时费力的事情。因此,为了尽量地避免拷贝,Dalvik 虚拟机将自己的堆划分为两部分。事实上,Dalvik 虚拟机的堆最初是只有一个的。也就是 Zygote 进程在启动过程中创建 Dalvik 虚拟机的时候,只有一个堆。但是当 Zygote 进程在 fork 第一个应用程序进程之前,会将已经使用了的那部分堆内存划分为一部分,还没有使用的堆内存划分为另外一部分。前者就称为 Zygote 堆,后者就称为 Active 堆。以后无论是 Zygote 进程,还是应用程序进程,当它们需要分配对象的时候,都在 Active 堆 上进行。这样就可以使得 Zygote 堆 尽可能少地被执行写操作,因而就可以减少执行写时拷贝的操作。在 Zygote 堆 里面分配的对象其实主要就是 Zygote 进程在启动过程中预加载的类、资源和对象了。这意味着这些预加载的类、资源和对象可以在 Zygote 进程和应用程序进程中做到长期共享。这样既能减少拷贝操作,还能减少对内存的需求。
堆的一些重要参数
| 中文名 | 英文名 | VM 参数 |
|---|---|---|
| 起始大小 | Starting Size | -Xms |
| 最大值 | Maximum Size | -Xmx |
| 增长上限值 | Growth Limit | -XX:HeapGrowthLimit |
| 最小空闲值 | Min Free | -XX:HeapMinFree |
| 最大空闲值 | Max Free | -XX:HeapMaxFree |
| 目标利用率 | Target Utilization | -XX:HeapTargetUtilization |
堆 起始大小 指定了 Davlik 虚拟机在启动的时候向系统申请的物理内存的大小。后面再根据需要逐渐向系统申请更多的物理内存,直到达到 最大值 为止。这是一种按需要分配策略,可以避免内存浪费,厂商会通过 dalvik.vm.heapstartsize 和 dalvik.vm.heapsize 这两个属性将它们设置为合适设备的值的
注意,虽然堆使用的 物理内存 是按需要分配的,但是它使用的 虚拟内存 的总大小却是需要在 Dalvik 启动的时候就确定的。这个虚拟内存的大小就等于堆的最大值
想象一下,如果不这样做的话,会出现什么情况。假设开始时创建的虚拟内存小于堆的最大值,由于实际情况是允许虚拟内存达到堆的最大值的,因此当开始时创建的虚拟内存无法满足需求时,那么就需要重新创建另外一块更大的虚拟内存。这样就需要将之前的虚拟内存的内容拷贝到新创建的更大的虚拟内存去,并且还要相应地修改各种辅助数据结构。这样太麻烦了,而且效率也太低了。因此就在一开始的时候,就创建一块与堆的最大值相等的虚拟内存
但是 Dalvik 虚拟机又希望能够动态地调整堆的可用最大值,于是就出现了一个称为 增长上限 的值,我们可以认为它是堆大小的 软限制,而前面所描述的最大值是堆大小的 硬限制。它主要是用来限制 Active Heap 无节制地增长到最大值的,而是要根据预先设定的 堆目标利用率 来控制 Active Heap 有节奏地增长到最大值。这样可以更有效地使用堆内存。想象一下,如果我们一开始 Active Heap 的大小设置为最大值,那么就很有可能造成已分配的内存分布在一个很大的范围。这样随着 Dalvik 虚拟机不断地运行,Active Heap 的内存碎片就会越来越来重。相反,如果我们施加一个 Soft Limit,那可以尽量地控制已分配的内存都位于较紧凑的范围内,可以有效地减少碎片
后三个用来确保每次 GC 之后,堆已用内存和空闲内存有一个合适的比例,这样可以尽量地减少 GC 的次数。举个例子说,堆的利用率为 U,最小空闲值为 MinFree 字节,最大空闲值为 MaxFree 字节。假设在某一次 GC 之后,存活对象占用内存的大小为 LiveSize。那么这时候堆的理想大小应该为 (LiveSize / U),且 (LiveSize + MinFree) <= (LiveSize / U) <= (LiveSize + MaxFree)
4 Type Of GC
Davlik 虚拟机定义了四种类型的 GC
/* Not enough space for an "ordinary" Object to be allocated. */
/* 在堆上分配对象时内存不足 */
extern const GcSpec *GC_FOR_MALLOC;
/* Automatic GC triggered by exceeding a heap occupancy threshold. */
/* 在已分配内存达到一定量之后触发 */
extern const GcSpec *GC_CONCURRENT;
/* Explicit GC via Runtime.gc(), VMRuntime.gc(), or SIGUSR1. */
/* 应用程序调用 System.gc、VMRuntime.gc接口或者收到 SIGUSR1 信号时触发 */
extern const GcSpec *GC_EXPLICIT;
/* Final attempt to reclaim memory before throwing an OOM. */
/* 在准备抛 OOM 异常之前进行的最后努力而触发的 GC */
extern const GcSpec *GC_BEFORE_OOM;每种 GC 通过成员属性控制 GC 细节
struct GcSpec {
/* If true, only the application heap is threatened. */
/* true - 仅仅回收 Active Heap,false - 同时回收 Active Heap 和 Zygote Heap */
bool isPartial;
/* If true, the trace is run concurrently with the mutator. */
/* true - 执行并行 GC,false - 执行非并行 GC */
bool isConcurrent;
/* Toggles for the soft reference clearing policy. */
/* true - 不回收软引用,false - 回收软引用引 */
bool doPreserve;
/* A name for this garbage collection mode. */
const char *reason;
};GC_FOR_MALLOC、GC_CONCURRENT 和 GC_BEFORE_OOM 三种类型的 GC 都是在分配对象的过程触发的:
- Dalvik 虚拟机在堆上分配对象的时候,如果分配失败会首先尝试
GC_FOR_MALLOC - GC 后再次进行对象的分配,如果失败这时候就得考虑先将堆的当前大小设置为 Dalvik 虚拟机启动时指定的堆最大值,再进行内存分配了(不应该是逐步增长?)
- 如果上一步内存分配还是失败,这时候就得出狠招
GC_BEFORE_OOM将 软引用 也回收掉 - 这是最后一次努力了,如果还是分配失败就抛出
OOM - 成功地在堆上分配到一个对象之后,就会检查
Active Heap当前已经分配的内存,如果大于阀值就会唤醒 GC 线程进行GC_CONCURRENT。这个阀值是一个比指定的 堆最小空闲内存 小 128K 的数值,也就是说当堆的 空闲内不足 时就会触发GC_CONCURRENT
Mark-Sweep(标记-清理 GC 算法)
顾名思义,Mark-Sweep (标记-回收)算法就是分为 Mark 和 Sweep两个阶段进行垃圾回收:
Mark阶段从GC ROOT开始递归地标记出当前所有被引用的对象Sweep阶段负责回收那些没有被引用的对象
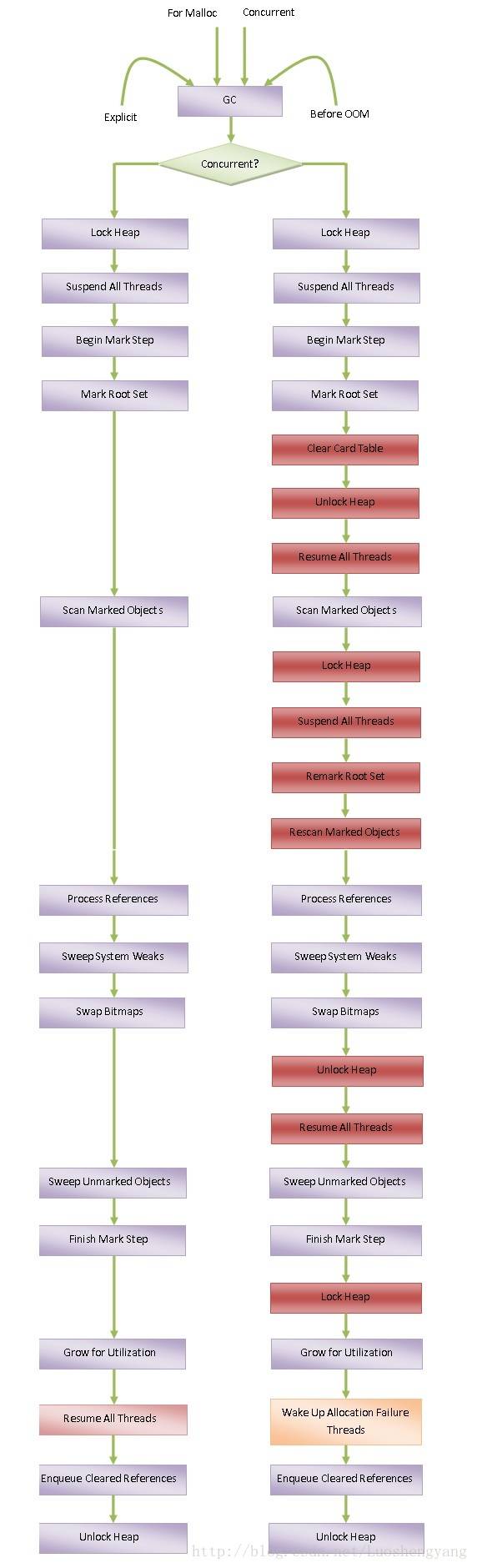
挂起其他线程
函数 lockThreadSuspend 尝试获取 gDvm._threadSuspendLock 锁。如果获取失败,就表明有其它线程也正在请求挂起 Dalvik 虚拟机中的线程,包括当前线程。每一个 Dalvik 虚拟机线程都有一个 Suspend Count 计数,每当它们都挂起的时候,对应的 Suspend Count 计数就会加 1,而当被唤醒时,对应的 Suspend Count 计数就会减 1。在获取 gDvm._threadSuspendLock 锁失败的情况下,当前线程按照一定的时间间隔检查自己的 Suspend Count,直到自己的 Suspend Count 等于 0,并且能成功获取 gDvm._threadSuspendLock 锁为止。这样就可以保证每一个挂起 Dalvik 虚拟机线程的请求都能够得到顺序执行。
从函数 lockThreadSuspend 返回之后,就表明当前线程可以执行挂起其它线程的操作了。它首先要做的第一件事情是遍历 Dalvik 虚拟机线程列表,并且调用函数 dvmAddToSuspendCounts 将列表里面的每一个线程对应的 Suspend Count 都增加1,但是除了当前线程之外。注意,在增加被挂起线程的 Suspend Count 计数之前,必须要获取 gDvm.threadSuspendCountLock 锁。这个锁的获取和释放可以通过函数 lockThreadSuspendCount 和 unlockThreadSuspendCount 完成
将被挂起线程的 Suspend Count 计数都增加 1 之后,接下来就是等待被挂起线程自愿将自己挂起来了。这是通过函数 waitForThreadSuspend 来实现。当一个线程自愿将自己挂起来的时候,会将自己的状态设置为非运行状态(THREAD_RUNNING),这样函数 waitForThreadSuspend 通过不断地检查一个线程的状态是否处于非运行状态就可以知道它是否已经挂起来了
那么,一个线程在什么情况才会自愿将自己挂起来呢?一个线程在执行的过程中,会在合适的时候检查自己的 Suspend Count 计数。一旦该计数值不等于 0,那么它就知道有线程请求挂起自己,因此它就会很配合地将自己的状态设置为非运行的,并且将自己挂起来。例如,当一个线程通过解释器执行代码时,就会周期性地检查自己的 Suspend Count 是否等于 0。这里说的周期性,实际上就是碰到 IF 指令、GOTO 指令、SWITCH 指令、RETURN 指令和 THROW 指令等时。
Heap Bitmap
堆的起始地址为 base,大小为 maxSize,由此我们就知道在堆上创建的对象的地址范围为 [base, maxSize)。 但是通过 C 库提供的 mspace_malloc 在堆分配内存时,得到的内存地址是以 8 bits 对齐的。这意味着我们只需要 (maxSize / 8) bits 来描述堆对象。结构体 HeapBitmap 的成员变量 bits 是一个类型为 unsigned long 的数组,也就是说数组中的每一个元素都可以描述 sizeof(unsigned long) 个对象的存活。在 32 位设备上,一个 unsigned long 占用 32 bits,这意味着需要一个大小为 (maxSize / 8 / 32) 的 unsigned long 数组来描述堆对象的存活。如果换成字节数来描述的话,就是说我们需要一块大小为 (maxSize / 8 / 32) × 4 的内存块来描述一个大小为 maxSize 的堆对象。
Live Bitmap 用来标记上一次 GC 时被引用的对象(也就是没有被回收的对象),Mark Bitmap 用来标记当前 GC Mark 阶段发现的被引用对象,那么在 Live Bitmap 标记为 1,但是在 Mark Bitmap 中标记为 0 的即为需要回收的对象
假设我们知道了一个对象的地址为 ptr,堆的起始地址为 base,那么就可以计算得到一个偏移值 offset。有了这个偏移值之后,可以计算得到用来描述该对象存活的 bit 位于 HeapBitmap->bits 的 unsigned long 数组的索引 index。有了这个 index 之后,我们就可以得到一个 unsigned long 值。接着再通过对象地址 ptr 的第 4 到第 8 位表示的数值为索引,在前面找到的 unsigned long 值取出相应的位,就可以得到该对象是否存活了。
相反,给出一个 HeapBitmap->bits 描述的 unsigned long 数组的索引 index,我们可以找到一个偏移值 offset,将这个偏移值加上堆的起始地址 base,就可以得到一个对象的地址 ptr
Mark Stack
在 GC Mark 阶段,Dalvik 虚拟机能过 递归方式 来标记对象。但是这不是通过函数的递归调用来实现的,而是借助一个称为 Mark Stack 的栈来实现的。具体来说,当我们标记完 GC ROOT 之后,就按照它们的地址从小到大的顺序标记它们所引用的其它对象。
假设有 A、B、C 和 D 四个对象,它的地址大小关系为 A < B < C < D,其中 B 和 D 是 GC ROOT,A 被 D 引用,C 没有被 B 和 D 引用。那么我们将依次遍历 B 和 D,当遍历到 B 的时候没有发现它引用其它对象,然后就继续向前遍历 D 对象,发现它引用了 A 对象。按照递归的算法,这时候除了标记 A 对象是正在使用之外,还应该去检查 A 对象有没有引用其它对象,然后又再检查它引用的对象有没有又引用其它的对象,一直这样遍历下去,这样就跟函数递归一样。(树的 深度优先 遍历算法)
更好的做法是将对象 A 记录在一个 Mark Stack 中,然后继续检查地址值比对象 D 大的其它对象。对于地址值比对象 D 大的其它对象,如果它们引用了一个地址值比它们小的其它对象,那么这些其它对象同样要记录在 Mark Stack 中。等到该轮检查结束之后,再回过头来检查记录在 Mark Stack里面的对象。然后又重复上述过程,直到 Mark Stack等于空为止。(树的 广度优先 遍历算法)
Concurrent GC
在 GC Mark 阶段,要求除了 GC 线程之外其它的线程都停止,否则的话就会可能导致不能正确地标记每一个对象。这种现象在 GC 中称为 Stop The World,会导致程序中止执行,造成停顿的现象。为了尽可能地减少停顿,我们必须要允许在 Mark 阶段有条件地允许程序的其它线程执行。这种 GC 称为 并行垃圾收集算法(Concurrent GC)。
为了实现 Concurrent GC,Mark 阶段又划分两个子阶段:
- 第一个子阶段只负责标记根集对象(
GC ROOT)。所谓的根集对象,就是指在 GC 开始的瞬间,被全局变量、栈变量和寄存器等引用的对象 - 有了这些根集变量之后,我们就可以顺着它们找到其余的被引用变量。例如,一个栈变量引了一个对象,而这个对象又通过成员变量引用了另外一个对象,那该被引用的对象也会同时标记为正在使用。这个 标记被根集对象引用的对象 的过程就是第二个子阶段
ART
odex
Davik 实现在 libdvm.so 中,ART 实现在 libart.so 中。Android 提供了一个系统属性 persist.sys.dalvik.vm.lib,如果等于 libdvm.so 就表示当前用的是 Dalvik,如果等于 libart.so 表示当前用的是 ART
Dalvik 执行的是 dex 字节码,ART 执行的是本地机器码
Dalvik 包含一个解释器用来执行 dex 字节码,而且从 Android 2.2 开始也包含有 JIT(Just-In-Time),用来在运行时动态地将执行频率很高的 dex 字节码翻译成本地机器码再执行。通过 JIT 就可以有效地提高 Dalvik 的执行效率。但是将 dex 字节码翻译成本地机器码是发生在应用程序的运行过程中的,并且应用程序每一次重新运行的时候都要做重做这个翻译工作的。因此即使用采用了 JIT,Dalvik 的总体性能还是不能与直接执行本地机器码的 ART 相比(ART 是 AOT)
PackageManagerService 在安装 APK 的过程中会通过 Installer.dexopt 对 dex 字节码进行优化,Installer 通过 socket 向守护进程 installd 发送一个 dexopt 请求,这个请求是由 installd 里面的函数 dexopt 来处理的
dexopt 首先是读取系统属性 persist.sys.dalvik.vm.lib,接着在 /data/dalvik-cache 创建一个 odex 文件。这个 odex 文件就是作为 dex 优化后的输出文件。再接下来,函数 dexopt 通过 fork 来创建一个子进程:
- 如果系统属性
persist.sys.dalvik.vm.lib的值等于libdvm.so,那么该子进程就会调用函数run_dexopt(最终调用命令/system/bin/dexopt)来将 dex 文件优化成odex文件 - 如果系统属性
persist.sys.dalvik.vm.lib的值等于libart.so,那么该子进程就会调用函数run_dex2oat(最终调用命令/system/bin/dex2oat)来将 dex 文件翻译成oat文件,实际上就是将 dex 字节码翻译成本地机器码,并且保存在一个oat文件中
无论是对 dex 字节码进行优化,还是将 dex 字节码翻译成本地机器码,最终得到的结果都是保存在相同名称的一个 odex 文件里面的,但是前者对应的是一个 dey 文件(表示这是一个优化过的 dex),后者对应的是一个 oat 文件(实际上是一个自定义的 elf 文件,里面包含的都是本地机器指令)
ART Heap
ART 的堆分为四个部分:Image Space、Zygote Space、Allocation Space 和 Large Object Space
其中 Image Space、Zygote Space 和 Allocation Space 是在地址上连续的空间,称为 Continuous Space,而 Large Object Space 是一些离散地址的集合,用来分配一些大对象,称为 Discontinuous Space
Space 还可以划分为 Allocable 和 Non-Allocable 两种。例如,Image Space 是不能分配新对象的(它是 boot oat 的文件映射),而 Zygote Space、Allocation Space 和 Large Object Space 是可以分配对象
Continuous Space 内部使用的内存块都是通过内存映射得到的,不过这块内存有可能是通过不同方式映射得到的。例如,Image Space 内部使用的内存块是通过内存映射 Image 文件得到的,而 Zygote Space 和 Allocation Space 内部使用的内存块是通过内存映射匿名共享内存得到
Image Space 空间包含了那些需要预加载的系统类对象,是对 /system/framework/boot.art 或者 /data/dalvik-cache/system@[email protected]@classes.dex 的内存映射
Zygote Space 和 Allocation Space 与 Dalvik 虚拟机垃圾收集机制中的 Zygote 堆和 Active 堆的作用是一样的。Zygote Space 在 Zygote 进程和应用程序进程之间共享的,而 Allocation Space 则是每个进程独占的。同样的,Zygote 进程一开始只有一个 Image Space 和一个 Zygote Space。在 Zygote 进程 fork 第一个子进程之前,就会把 Zygote Space 一分为二,原来的已经被使用的那部分堆还叫 Zygote Space,而未使用的那部分堆就叫 Allocation Space。以后的对象都在 Allocation Space 上分配。
只要满足以下三个条件,就在 Large Object Space 上分配,否则就在 Zygote Space 或者 Allocation Space 上分配:
- 请求分配的内存大于等于
Heap->large_object_threshold_,它等于3 * kPageSize即 3 个页面的大小 - 已经从
Zygote Space划分出Allocation Space,即Heap->have_zygote_space_ == true - 被分配的对象是一个原子类型数组,即 byte 数组、int 数组和 boolean 数组等
ART 运行时的堆 Heap 有以下重要的成员变量
| name | desc |
|---|---|
| mark_sweep_collectors_ | 保存了六种 Mark-Sweep 垃圾收集器的向量 |
| continuous_spaces_ | 保存了三个在地址空间上连续的 Image Space、Zygote Space 和 Allocation Space |
| concurrent_gc_ | bool,描述是否支持并行 GC,可以通过 -Xgc 来指定 |
| parallel_gc_threads_ | 指定在 GC 暂停阶段用来同时执行 GC 任务的线程数,通过 -XX:ParallelGCThreads指定。默认 CPU 核心数减 1 |
| conc_gc_threads_ | 非 GC 暂停阶段用来同时执行 GC 任务的线程数,通过 -XX:ConcGCThreads 指定 |
| discontinuous_spaces_ | 向量,保存了在地址空间上不连续的 Large Object Space |
| alloc_space_ | 指向 Allocation Space |
| large_object_space_ | 指向 Large Object Space |
| card_table_ | Card Table |
| image_mod_union_table_ | 记录 GC 并行阶段在 Image Space 的对象对在 Zygote Space 和 Allocation Space 上分配的对象的引用 |
| zygote_mod_union_table_ | 记录 GC 并行阶段在 Zygote Space 的对象对在 Allocation Space 上分配的对象的引用 |
| mark_stack_ | Mark Stack,用来在 GC 过程中实现递归对象标记 |
| allocation_stack_ | Allocation Stack,用来记录上一次 GC 后分配的对象,用来实现类型为 Sticky 的 Mark Sweep Collector |
| live_stack_ | Live Stack,配合 allocation_stack_ 一起使用,用来实现类型为 Sticky 的 Mark Sweep Collector |
| mark_bitmap_ | 与 Dalvik Mark Bitmap 作用是一样的,用来标记当前 GC 之后还存活的对象 |
| live_bitmap_ | 与 Dalvik Live Bitmap 作用是一样的,用来标记上一次 GC 之后还存活的对象 |
Space 有以下三种回收策略
// See Space::GetGcRetentionPolicy.
enum GcRetentionPolicy {
// Objects are retained forever with this policy for a space.
// 永远不会进行垃圾回收的 Space,例如 Image Space
kGcRetentionPolicyNeverCollect,
// Every GC cycle will attempt to collect objects in this space.
// 每一次 GC 都会尝试回收垃圾的 Space,例如 Allocation Space
kGcRetentionPolicyAlwaysCollect,
// Objects will be considered for collection only in "full" GC cycles, ie faster partial
// collections won't scan these areas such as the Zygote.
// 只有执行类型为 kGcTypeFull 的 GC 才会进行垃圾回收的 Space,例如 Zygote Space
kGcRetentionPolicyFullCollect,
};在堆上分配对象
流程跟 Dalvik 差不多:
- Dalvik 虚拟机在堆上分配对象的时候,如果分配失败会首先尝试
GC_FOR_MALLOC - GC 后再次进行对象的分配,如果失败这时候就得考虑先将堆的当前大小设置为 Dalvik 虚拟机启动时指定的堆最大值,再进行内存分配了(不应该是逐步增长?)
- 如果上一步内存分配还是失败,这时候就得出狠招
GC_BEFORE_OOM将 软引用 也回收掉 - 这是最后一次努力了,如果还是分配失败就抛出
OOM - 成功地在堆上分配到一个对象之后,就会检查
Active Heap当前已经分配的内存,如果大于阀值(Heap->concurrent_start_bytes_)就会唤醒 GC 线程进行GC_CONCURRENT。这个阀值是一个比指定的 堆最小空闲内存 小 128K 的数值,也就是说当堆的 空闲内不足 时就会触发GC_CONCURRENT
ART GC
ART 有以下三种 GC Collector
// The type of collection to be performed. The ordering of the enum matters, it is used to
// determine which GCs are run first.
enum GcType {
// Placeholder for when no GC has been performed.
kGcTypeNone,
// Sticky mark bits GC that attempts to only free objects allocated since the last GC.
// StickyMarkSweep 类型的垃圾收集器,用来收集上次 GC 以来分配的对象
kGcTypeSticky,
// Partial GC that marks the application heap but not the Zygote.
// PartialMarkSweep 类型的垃圾收集器,用来收集在 Allocation Space 上分配的对象
kGcTypePartial,
// Full GC that marks and frees in both the application and Zygote heap.
// MarkSweep 类型的垃圾收集器,用来收集在 Zygote Space 和 Allocation Space 上分配的对象
kGcTypeFull,
// Number of different GC types.
kGcTypeMax,
};ART 比 Dalvik 多了一个称 Mod Union Table 的概念。Mod Union Table 是与 Card Table 配合使用的,用来记录在一次 GC 过程中,不会被回收的 Space 对象对会被回收的 Space 对象引用。例如,Image Space 对象对 Zygote Space 和 Allocation Space 对象的引用,以及 Zygote Space 对象对 Allocation Space 对象的引用。
五个守护线程
java.lang.Daemons 类在加载的时候,会启动五个与堆或者 GC 相关的守护线程
public final class Daemons {
public static void start() {
ReferenceQueueDaemon.INSTANCE.start();
FinalizerDaemon.INSTANCE.start();
FinalizerWatchdogDaemon.INSTANCE.start();
HeapTrimmerDaemon.INSTANCE.start();
GCDaemon.INSTANCE.start();
}
}| 英文 | 中文 | 描述 |
|---|---|---|
| ReferenceQueueDaemon | 引用队列守护线程 | 在创建 Reference 时可以关联一个 ReferenceQueue,当引用对象被 GC 回收的时候,Reference 就会被加入到 ReferenceQueue。这个入队操作就是由 ReferenceQueueDaemon 来完成的。这样应用程序就可以知道那些被引用对象引用的对象已经被回收了 |
| FinalizerDaemon | 析构守护线程 | 对于重写了成员函数 finalize 的对象,它们被 GC 决定回收时并没有马上被回收,而是被放入到一个队列中,等待 FinalizerDaemon 守护线程去调用它们的成员函数 finalize 然后再被回收 |
| FinalizerWatchdogDaemon | 析构监护守护线程 | 用来监控 FinalizerDaemon 线程的执行。一旦检测到在执行成员函数 finalize 时超出一定的时间限制,那么就会退出 VM |
| HeapTrimmerDaemon | 堆裁剪守护线程 | 用来执行裁剪堆的操作,也就是用来将那些空闲的堆内存归还给系统(compacting) |
| GCDaemon | 并行 GC 线程 | 用来执行并行 GC |
Compacting GC
Android 4.4 支持 Mark-Sweep GC,到了 Android 5.0 增加了对 Compacting GC 的支持。所谓 Compacting GC,就是在进行 GC 的时候同时对堆空间进行 压缩 以消除碎片,因此它的堆空间利用率就更高。但是也正因为要对堆空间进行压缩,导致它的效率不如 Mark-Sweep GC,而且会导致对象的地址发生变化
在以往的 Mark-Sweep GC 时由于碎片而产生的内存不足问题是解决不了的,只能让应用程序 OOM。但是有了 Compacting GC 之后就可以在应用程序 OOM 之前再作一次努力,那就是对原来的堆空间进行压缩一下,再尝试进行分配,这样就可以提高成功分配内存的概率
Compacting GC 增加了一些额外的参数:
| 参数名 | 解释 |
|---|---|
| -XX:NonMovingSpaceCapacity | Non-Moving Space 的大小,默认大小为 kDefaultNonMovingSpaceCapacity(64MB) |
| -Xgc | Foreground GC 的类型,可选:Concurrent Mark-Sweep GC、Semi-Space GC 或者 Generational Semi-Space GC |
| -XX:BackgroundGC | Background GC 的类型,比 Foreground GC 多了 Homogeneous-Space-Compact,默认就与 Foreground GC 一样 |
| -XX:EnableHSpaceCompactForOOM / -XX:DisableHSpaceCompactForOOM | 是否在 OOM 时执行 Homogeneous-Space-Compact |
Compacting GC 通过移动和整理对象以实现压缩:把散乱的对象逐个移动到一块空闲的内存空间,因为整块空间都是空闲的,所以可以紧凑地将它们放在一起,这个空间叫 Bump Pointer Space
(Generational) Semi-Space GC
Semi-Space GC 由两个 Bump Pointer Space 组成,分别叫做 From Space 和 To Space,其中对象的分配发生在 From Space中。Bump Pointer Space 有一个指针 end_ 始终指向下一次要分配的内存块的起始地址,因此在 Bump Pointer Space 上分配内存的逻辑是很简单的,只要指针 end_ 向前移动指定的大小即可,这也是 Bump Pointer 的由来
当 From Space 不能满足内存分配要求时,就会触发一次 Semi-Space GC,结果就是 From Space 和 To Space 互换了位置,并且原来在 From Space 上的 Live Object 按地址值 从小到大 的顺序移动到了原来的To Space上去(这不就是 JVM Young Generation 里的 Survivor 嘛)
Generational Semi-Space GC 涉及到三个 Space,其中两个是 Bump Pointer Space,另外一个是 Promote Space
Generational Semi-Space GC 与 Semi-Space GC 基本相同,只不过会考虑到 对象的年龄。如果一个对象在多次 GC 中都能存活下来,那么就会将它移动到一个 Promote Space 中去。这相当于是简单地将对象划分为 新生代 和 老生代,即在上一次 GC 之前分配的对象属于老生代,而在上一次 GC 之后分配的对象属于新生代。由于 Promote Space 是一个 Non-Moving Space,以后在这个 Space 上的对象不会再被移动。通过这种方式就可以有效地减少在 Generational Semi-Space GC 中要移动的对象的个数,从而提高 GC 效率(这不就是 JVM Old Generation)
Semi-Space GC 和 Generational Semi-Space GC 使用的是同一个垃圾收集器,保存在 Heap->semi_space_collector_,From Space 和 To Space 分别是 Heap->bump_pointer_space_ 和 Heap->temp_space_(它们都是 Bump Pointer Space),当 GC 执行完毕交换 From Space 和 To Space
只能执行类型为 kGcTypeFull 的 GC
Mark-Compact GC
- 只需一个
Bump Pointer Space来压缩内存,当 GC 执行完成之后,原来位于Bump Pointer Space上的仍然存活的对象会被依次移动至左侧,并且按地址从小到大紧凑地排列在一起 - 执行过程分为 初始化、标记、回收 和 结束 四个阶段,对应的函数分别为
MarkCompact的InitializePhase、MarkingPhase、ReclaimPhase和FinishPhase,其中标记和回收阶段是在挂起其它线程的前提下进行的 Image Space和Zygote Space是不进行垃圾回收的,同时也意味着Non Moving Space、Bump Pointer Space和Large Object Space需要进行垃圾回收- 标记阶段并没有对
Bump Pointer Space的存活对象进行移动,而是在接下来的回收阶段再执行此操作 - 能够执行
kGcTypeSticky、kGcTypePartial和kGcTypeFull三种类型的 GC
Homogeneous Space Compact
所谓的 同构空间压缩特性(Homogeneous Space Compact),是针对 Mark-Sweep GC 而言的。一个 Space 需要有 Main 和 Backup 之分。执行同构空间压缩时,将 Main Space 的对象移动至 Backup Space 中去,再将 Main Space 和 Backup Space 进行交换,这样就达到压缩空间,即减少内存碎片的作用。
Non-Moving Space
在 Compacting GC 中涉及到对象的移动,但是有些对象例如类对象(Class)、类方法对象(ArtMethod)和类成员变量对象(ArtField),它们一经加载后基本上就会一直存在。因此频繁对此类对象进行移动是无益的,我们需要将它们分配在一个不能移动的 Space 中以减少在 Compacting GC 需要处理的对象的数量
Foreground GC 和 Background GC
ART 既支持 Mark-Sweep GC 又支持 Compacting GC。其中 Mark-Sweep GC 执行效率更高但是存在内存碎片问题,而 Compacting GC 执行效率较低但是不存在内存碎片问题。ART 通过引入 Foreground GC 和 Background GC 的概念来对这两种 GC 进行扬长避短,分别用 -Xgc 和 -XX:BackgroundGC 指定
顾名思义,Foreground GC 就是应用程序在前台运行时执行的 GC,Background GC 就是应用程序在后台运行时执行的 GC。应用程序在前台运行时,响应性是最重要的,因此也要求执行的GC是高效的。相反,应用程序在后台运行时,响应性不是最重要的,这时候就适合用来解决堆的内存碎片问题。因此,Mark-Sweep GC 适合作为 Foreground GC 而 Compacting GC 适合作为 Background GC
AMS 清楚地知道应用程序当前是在前台运行还是后台运行,所以由它负责触发切换前后台 GC 的操作
ApplicationThread.scheduleLaunchActivity
ApplicationThread.updateProcessState(int processState, boolean fromIpc) {
synchronized (this) {
if (mLastProcessState != processState) {
mLastProcessState = processState;
// 用户可感知/用户不可感知
final int DALVIK_PROCESS_STATE_JANK_PERCEPTIBLE = 0;
final int DALVIK_PROCESS_STATE_JANK_IMPERCEPTIBLE = 1;
int dalvikProcessState = DALVIK_PROCESS_STATE_JANK_IMPERCEPTIBLE;
// <= PROCESS_STATE_IMPORTANT_FOREGROUND 表示前台进程,用户可见可交互
if (processState <= ActivityManager.PROCESS_STATE_IMPORTANT_FOREGROUND) {
dalvikProcessState = DALVIK_PROCESS_STATE_JANK_PERCEPTIBLE;
}
VMRuntime.getRuntime().updateProcessState(dalvikProcessState);
......
}
}
}
// AMS 定义了 14 种进程的状态,越小越重要
public class ActivityManager {
/** @hide Process is a persistent system process. */
public static final int PROCESS_STATE_PERSISTENT = 0;
/** @hide Process is a persistent system process and is doing UI. */
public static final int PROCESS_STATE_PERSISTENT_UI = 1;
/** @hide Process is hosting the current top activities. Note that this covers
* all activities that are visible to the user. */
public static final int PROCESS_STATE_TOP = 2;
/** @hide Process is important to the user, and something they are aware of. */
public static final int PROCESS_STATE_IMPORTANT_FOREGROUND = 3;
/** @hide Process is important to the user, but not something they are aware of. */
public static final int PROCESS_STATE_IMPORTANT_BACKGROUND = 4;
/** @hide Process is in the background running a backup/restore operation. */
public static final int PROCESS_STATE_BACKUP = 5;
/** @hide Process is in the background, but it can't restore its state so we want
* to try to avoid killing it. */
public static final int PROCESS_STATE_HEAVY_WEIGHT = 6;
/** @hide Process is in the background running a service. Unlike oom_adj, this level
* is used for both the normal running in background state and the executing
* operations state. */
public static final int PROCESS_STATE_SERVICE = 7;
/** @hide Process is in the background running a receiver. Note that from the
* perspective of oom_adj receivers run at a higher foreground level, but for our
* prioritization here that is not necessary and putting them below services means
* many fewer changes in some process states as they receive broadcasts. */
public static final int PROCESS_STATE_RECEIVER = 8;
/** @hide Process is in the background but hosts the home activity. */
public static final int PROCESS_STATE_HOME = 9;
/** @hide Process is in the background but hosts the last shown activity. */
public static final int PROCESS_STATE_LAST_ACTIVITY = 10;
/** @hide Process is being cached for later use and contains activities. */
public static final int PROCESS_STATE_CACHED_ACTIVITY = 11;
/** @hide Process is being cached for later use and is a client of another cached
* process that contains activities. */
public static final int PROCESS_STATE_CACHED_ACTIVITY_CLIENT = 12;
/** @hide Process is being cached for later use and is empty. */
public static final int PROCESS_STATE_CACHED_EMPTY = 13;
}
VMRuntime.updateProcessState(int state)
VMRuntime_updateProcessState(JNIEnv* env, jobject, jint process_state)
Heap::UpdateProcessState(ProcessState process_state)
Heap::RequestCollectorTransition(CollectorType desired_collector_type, uint64_t delta_time)
Heap::SignalHeapTrimDaemon(Thread* self)
Daemons.requestHeapTrim()上面说过 ART 启动后加载 java.lang.Daemons 时,会启动五个守护线程,其中有一个是 HeapTrimmerDaemon 负责压缩堆内存,其实它也负责切换 GC,并且在过程中根据情况有可能在切换 GC 前执行一次 compacting
public final class Daemons {
public static void requestHeapTrim() {
synchronized (HeapTrimmerDaemon.INSTANCE) {
HeapTrimmerDaemon.INSTANCE.notify();
}
}
}切换至 Semi-Space GC
这时候原来的 GC 只能为 Mark-Sweep GC 或者 Concurrent Mark-Sweep GC,此时 ART 堆由 Image Space、Zygote Space、Non Moving Space、Main Space、Main Backup Space 和 Large Object Space 组成。要做的是将 Main Space 上的存活对象移动至一个新创建的 Bump Pointer Space 上去,也就是说这时候的 Source Space 为 Main Space,而 Target Space 为 Bump Pointer Space。
Main Space 就保存在 Heap->main_space_,因此就很容易可以获得。但是这时候是没有现成的 Bump Pointer Space 的,因此就需要创建一个。由于这时候的 Main Backup Space 是闲置的,并且当 GC 切换完毕它也用不上了,因此我们就可以将 Main Backup Space 底层使用的内存块获取回来,然后再封装成一个 Bump Pointer Space。注意这时候创建的 Bump Pointer Space 也是作为 GC 切换完成后的 From Space 使用的,因此除了要将它保存在 Heap->bump_pointer_space_ 之外,还要将它添加到 ART 的 Space 列表中去
这时候 Source Space 和 Target Space 均已准备完毕,因此就可以执行 Heap->Compact 了。执行完毕还需要做一系列的清理工作,包括:
- 删除
Main Space - 删除
Main Backup Space - 创建一个
Bump Pointer Space保存在Heap->temp_space_,作为 GC 切换完成后的 To Space 使用(注意这个 To Space 底层使用的内存块是来自于原来的 Main Space)
这意味着将从 (Concurrent)Mark-Sweep GC 切换为 Semi-Space GC 之后,原来的 Main Space 和 Main Backup Space 就消失了,并且多了两个 Bump Pointer Space,其中一个作为 From Space,另外一个作为 To Space,并且 From Space 上的对象来自于原来的 Main Space 的存活对象
切换至 (Concurrent)Mark-Sweep GC
这时候原来的 GC 只能为 Semi-Space GC、Generational Semi-Space GC 或者 Mark-Compact GC,ART 堆由 Image Space、Zygote Space、Non Moving Space、Bump Pointer Space、Temp Space 和 Large Object Space 组成。要做的是将 Bump Pointer Space 上的存活对象移动至一个新创建的 Main Space 上去,也就是说这时候的 Source Space 为 Bump Pointer Space,而 Target Space 为 Main Space
Bump Pointer Space 就保存在 Heap->bump_pointer_space_,因此就很容易可以获得。但是这时候是没有现成的 Main Space 的,因此就需要创建一个。由于这时候的 Temp Space 是闲置的,并且当 GC 切换完毕它也用不上了,因此我们就可以将 Temp Space 底层使用的内存块获取回来,然后再封装成一个 Main Space,这是通过调用 Heap->CreateMainMallocSpace 来实现的。注意,它在执行的过程中会将创建的 Main Space 保存在 Heap->main_space_,并且作为 GC 切换完成后 (Concurrent)Mark-Sweep GC 的 Main Space使用的,因此就还要将它添加到 ART 堆的 Space 列表中去
这时候 Source Space 和 Target Space 均已准备完毕,可以执行 Heap->Compact了。执行完毕还需要做一系列的清理工作,包括:
- 删除
Bump Pointer Space - 删除
Temp Space - 创建一个
Main Backup Space保存在Heap->main_space_backup_,这是通过调用Heap->CreateMallocSpaceFromMemMap实现的,并且该Main Backup Space底层使用的内存块是来自于原来的Bump Pointer Space的