Lock(一)AQS 基础
自旋锁(Spin Lock)
获得锁的时候,不阻塞线程,而是跟平常一样继续获得 CPU 时间,继续执行代码/逻辑,那就是自旋锁;比如下面的 lock()
// 一个简单的自旋锁的实现
class SpinLock {
private val cas = AtomicReference<Thread>()
fun lock() {
while (!cas.compareAndSet(null, Thread.currentThread())) {}
}
fun unlock() {
cas.compareAndSet(Thread.currentThread(), null)
}
}MCS 锁
上面的自旋锁容易出现「饥饿」问题,因为所有线程同时争抢一个锁,如果一直有线程加入到争抢的过程中来,那么可能会出现某一个或多个线程总是抢不到锁的情况
而 MCS 在自旋的基础上,引入了「排队」的概念(基于链表)
acquire_lock,L是链尾节点,I是当前线程所使用的节点,fetch_and_store相当于原子性地把 I 添加到链尾,并对I→locked进行自旋release_lock,将I→next→locked置为false,从而使下一个线程获得锁(跳出自旋)
那么所有未获得锁的线程都会按顺序排成一队(通过 I→next 形成的单向链表),并对 I→locked 自旋,这就是排队自旋锁
获得锁的线程负责将锁传递给下一个未获得锁的线程(I→next→locked := false)

CLH 锁
它减少释放锁时的自旋开销:
- MCS 锁的持有进程在让渡锁的所有权时,由于需要关心自己的后继结点是否存在以及是否会被突然添加,所以多了一些负担
- MCS 锁在持有进程在让渡锁的所有权时,由于已经知道后继结点肯定只能监控自己在入队时就设置好的结点,所以无需关心是否存在后继结点,只需要修改自己预留给后继结点监控的队列结点状态即可。
MCS 实现了基于 FIFO 的优先级,而 CLH 可以实现自定义的优先级
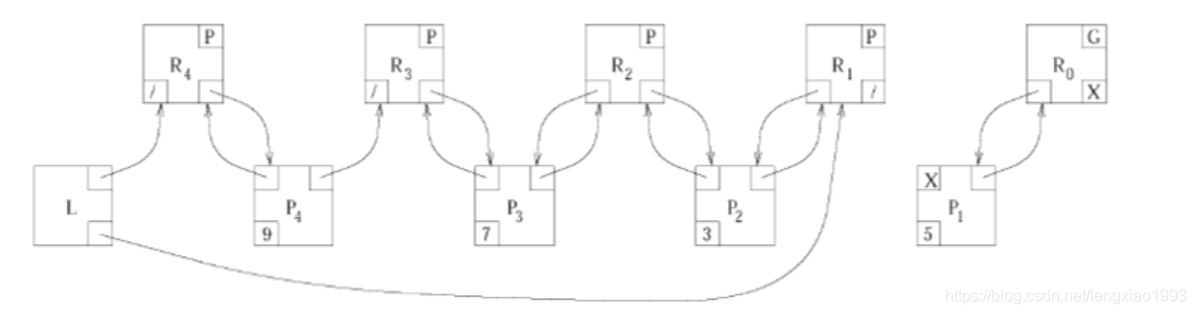
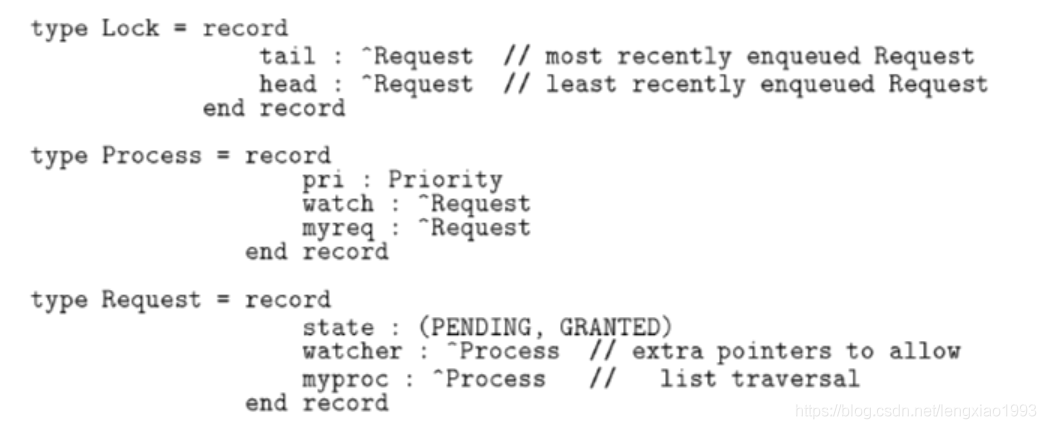
CLH 锁的排队队列是个双向链表,Lock.head 和 Lock.tail 分别是表头和表尾
Process.watch 是当前线程用来自旋的,Process.myreq 留给下一个线程进行自旋;比如线程 P2 在 P2.watch 上自旋,同时 P2.watch 又是 P1.myreq;而 P2.myreq 则是 P3.watch,P3 在 P3.watch 上自旋
Request.watcher 表示那个线程在对它自旋,Request.myproc 表示自旋线程的上一个线程
从表头开始遍历线程:Lock.head.watcher → Process.myreq.watcher → Process.myreq.watcher→ …
从表尾开始遍历线程:Lock.tail.myproc → Process.watch.myproc → Process.watch.myproc → …
request_lock(获得锁),将 P.myreq 添加到队尾,并在 P.watch(既是上一个队尾,也是上一个线程的 Process.myreq) 上自旋
grant_lock(释放锁),从头开始遍历排队的线程,找到优先级最高的线程(Process.pri,不仅仅是 FIFO),将它的 Process.watch.state := GRANTED 从而使它跳出自旋(将锁的所有权转移给它)